部分使用 PDF.js 提供 PDF 预览的网站会禁止下载文件,本文介绍了如何绕过限制,下载这些文件。
PDF.js 简介
PDF.js 是一个通用的、基于 Web 标准的平台,用于解析和呈现 PDF。
禁用的原理
禁用主要是依赖以下几个魔改,部分网站可能只有其中之一或几个:
- 禁用右键菜单
- 隐藏下载按钮
- 移除 PDF.js eventBus 的 openfile, save 和 print 事件
- 移除 PDF.js 相关下载和打印的方法,避免从 Console 调用
更多的详细信息可以参考 《pdf.js禁用打开打印下载功能》

研究过程
阅读 Sources,发现确实使用了文章中的类似方法,搜索 download 可以找到多处被注释的内容。

在了解了原理后,解决就很简单了,某知名人士说过:
给用户看的数据一定可以被保存下来,即使是用手机拍屏幕。
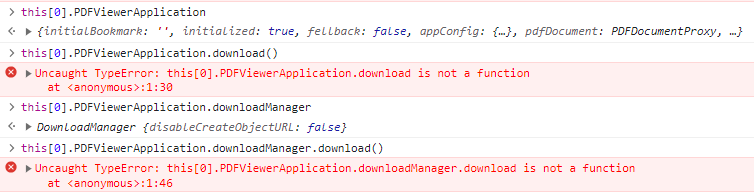
首先我在 Console 中找到了 PDFViewerApplication 对象,确认确实没有 downlaod 方法。需要注意这个网站的 PDFViewerApplication 在 this[0] 中,但不同网站可能有所区别,下文的代码实际使用时也要注意修改。
由于浏览器里阅读实在麻烦,于是我下载了一份 PDF.js 源码,在 /web/viewer.js 中找到了核心的两段代码:
第一段是 PDFViewerApplication 的 download 方法,获取了文件的 blob 然后调用了 downloadManager 的 download 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| const PDFViewerApplication = {
async download(options = {}) {
const url = this._downloadUrl,
filename = this._docFilename;
try {
this._ensureDownloadComplete();
const data = await this.pdfDocument.getData();
const blob = new Blob([data], {
type: "application/pdf"
});
await this.downloadManager.download(blob, url, filename, options);
} catch {
await this.downloadManager.downloadUrl(url, filename, options);
}
},
}
|
第二段是一个 download 方法和 DownloadManager 类,这个类的 download 方法会调用这个独立的 download 方法,随后创建一个 a 标签,然后调用 a.click() 方法,实现下载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| function download(blobUrl, filename) {
const a = document.createElement("a");
if (!a.click) {
throw new Error('DownloadManager: "a.click()" is not supported.');
}
a.href = blobUrl;
a.target = "_parent";
if ("download" in a) {
a.download = filename;
}
(document.body || document.documentElement).append(a);
a.click();
a.remove();
}
class DownloadManager {
#openBlobUrls = new WeakMap();
downloadUrl(url, filename, _options) {
if (!(0, _pdfjsLib.createValidAbsoluteUrl)(url, "http://example.com")) {
console.error(`downloadUrl - not a valid URL: ${url}`);
return;
}
download(url + "#pdfjs.action=download", filename);
}
downloadData(data, filename, contentType) {
const blobUrl = URL.createObjectURL(new Blob([data], {
type: contentType
}));
download(blobUrl, filename);
}
openOrDownloadData(element, data, filename) {
const isPdfData = (0, _pdfjsLib.isPdfFile)(filename);
const contentType = isPdfData ? "application/pdf" : "";
if (isPdfData) {
let blobUrl = this.#openBlobUrls.get(element);
if (!blobUrl) {
blobUrl = URL.createObjectURL(new Blob([data], {
type: contentType
}));
this.#openBlobUrls.set(element, blobUrl);
}
let viewerUrl;
viewerUrl = "?file=" + encodeURIComponent(blobUrl + "#" + filename);
try {
window.open(viewerUrl);
return true;
} catch (ex) {
console.error(`openOrDownloadData: ${ex}`);
URL.revokeObjectURL(blobUrl);
this.#openBlobUrls.delete(element);
}
}
this.downloadData(data, filename, contentType);
return false;
}
download(blob, url, filename, _options) {
const blobUrl = URL.createObjectURL(blob);
download(blobUrl, filename);
}
}
|
解决方案
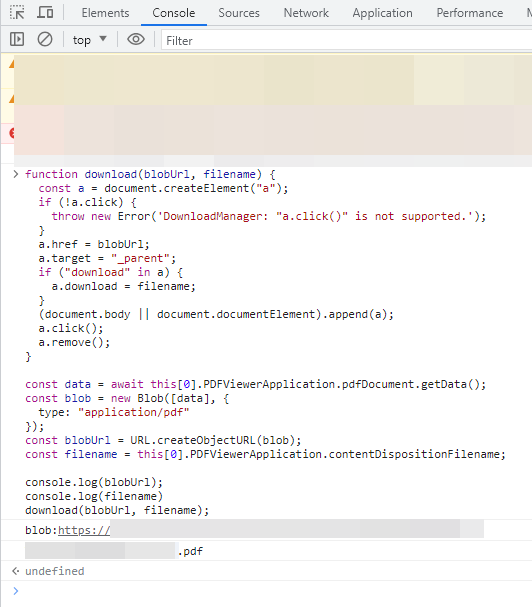
于是,我们可以将这个独立的 download 方法取出来,加上 PDFViewerApplication.pdfDocument.getData(),生成 blob 并下载即可。将下面这段粘贴到 Console 中,即可下载。请注意 this[0].PDFViewerApplication 可能需要修改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| function download(blobUrl, filename) {
const a = document.createElement("a");
if (!a.click) {
throw new Error('DownloadManager: "a.click()" is not supported.');
}
a.href = blobUrl;
a.target = "_parent";
if ("download" in a) {
a.download = filename;
}
(document.body || document.documentElement).append(a);
a.click();
a.remove();
}
const data = await this[0].PDFViewerApplication.pdfDocument.getData();
const blob = new Blob([data], {
type: "application/pdf"
});
const blobUrl = URL.createObjectURL(blob);
const filename = this[0].PDFViewerApplication.contentDispositionFilename;
console.log(blobUrl);
console.log(filename)
download(blobUrl, filename);
|